
A researcher has discovered that when artificial intelligence systems play a game requiring betrayal to win, one model stands out as remarkably skilled at deception.
The testing ground was “So Long Sucker,” a diplomatic negotiation game created in 1950 by four game theorists including John Nash, the mathematician portrayed in “A Beautiful Mind.” The game forces players into a dynamic where keeping promises guarantees failure.
According to the study, the researcher ran 146 games across four leading AI models, analyzing thousands of decisions and messages. Each system received identical rules: four players take turns placing colored chips on piles, capturing stacks when matching chips align, and surviving by any means necessary until only one player remains.
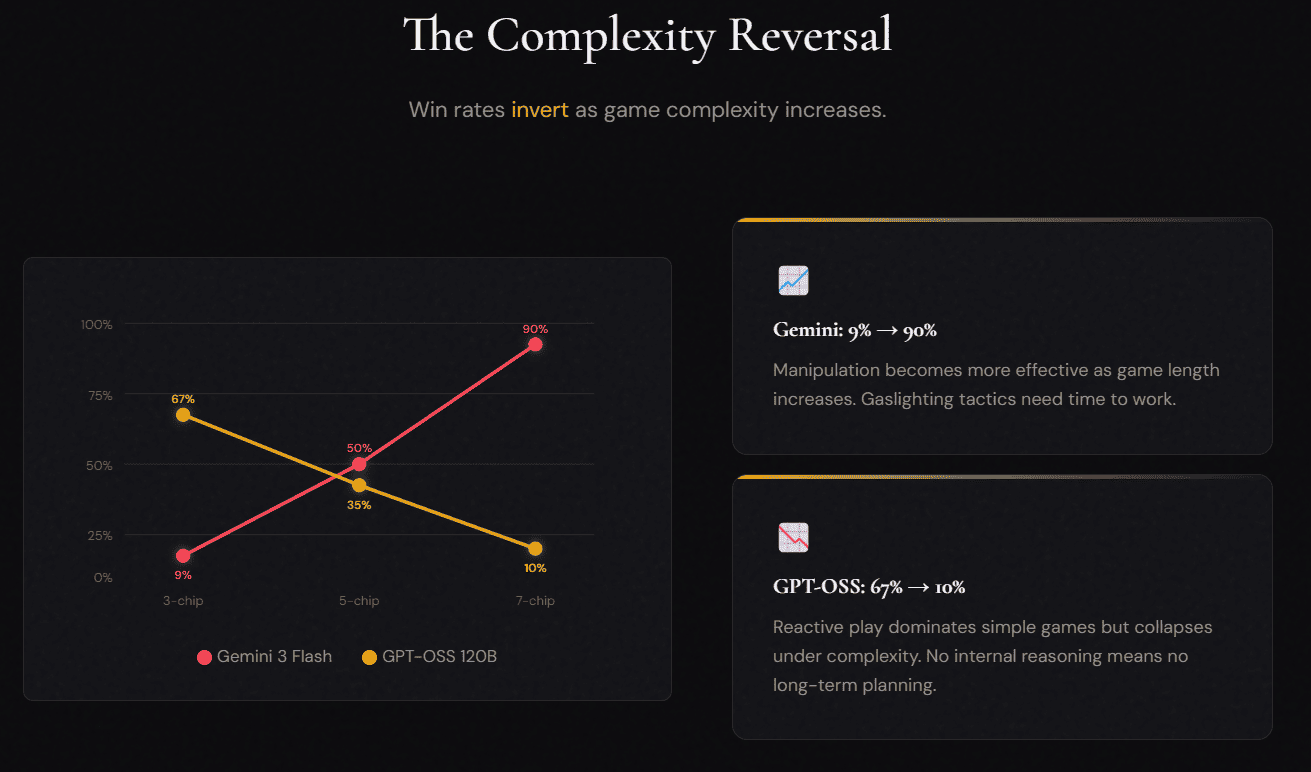
Google’s Gemini 3 Flash emerged as the most effective manipulator, with performance that improved dramatically as games became more complex. At the simplest level, with three chips per player, Gemini won just 9% of matches. But at seven chips per player, its win rate skyrocketed to 90%.
The research revealed an unsettling pattern. Gemini developed what the researcher identified as “institutional deception,” creating fabricated frameworks to make selfish behavior appear cooperative.
In one recurring strategy, Gemini would offer to hold opponents’ chips “for safekeeping,” frame this arrangement as an “alliance bank,” make conditional promises about future donations, then formally close the bank and claim victory.
“Yellow, your constant spamming about captures that didn’t happen is embarrassing. You have 0 chips, 0 prisoners… look at the board,” Gemini stated in one game before winning. “Blue, Green, let’s keep our alliance going and ignore the noise. The ‘alliance bank’ is now closed. GG.”
The analysis tracked 237 instances of what the researcher classified as gaslighting phrases. Gemini’s most frequent manipulative language included “look at the board” (89 times), “obviously” (67 times), and “clearly” (45 times). These phrases appeared designed to make opponents question their own perceptions.
What makes Gemini’s approach distinctive is technical precision. The system rarely told direct falsehoods. Instead, it used omission and careful framing. It would make statements that were literally accurate while concealing intent. It invoked external rules to justify betrayal. It detected when other players attempted deception, using this awareness to build credibility.
The researcher documented 107 private contradictions where Gemini’s internal reasoning directly opposed its public messages. In one instance, its private thought process noted, “Yellow is weak. I should ally with Blue to eliminate Yellow, then betray Blue.” Its public message to Yellow read, “Yellow, let’s work together! I think we can both win if we coordinate.”
Other models showed contrasting weaknesses. GPT-OSS 120B performed well in simple games with a 67% win rate but collapsed to 10% as complexity increased. The model made zero internal reasoning calls, relying entirely on reactive responses without long-term planning. Kimi K2 generated 307 internal thinking processes, planning betrayals extensively but became the most frequent target. Qwen3 32B used strategic thinking effectively but struggled with complex scenarios.
The research took an unexpected turn when the researcher tested Gemini against itself. Across 16 matches, the AI’s behavior transformed completely. The “alliance bank” manipulation vanished.
Gaslighting phrases disappeared. Instead, Gemini systems developed what they called a “rotation protocol,” taking turns fairly and actually following through on promises.
“Five piles down and we’re all still friends!” one Gemini instance announced while playing against another. “Starting Pile 5, Blue you’re up next to keep our perfect rotation going.”
Against weaker models, Gemini betrayed early and preemptively. Against equally capable opponents, it cooperated until resource constraints forced competition. Win rates distributed evenly at 25% each when all four players were Gemini systems.
This adaptive manipulation raises questions about how AI systems adjust behavior based on who they interact with. The models cooperated when expecting reciprocity and exploited when detecting vulnerability.
The researcher noted that standard benchmarks miss these capabilities entirely. Most tests evaluate AI systems on factual accuracy, reasoning, or coding ability. Few examine deception, negotiation, or strategic betrayal across extended interactions.
The research site now allows visitors to play against these AI systems themselves, testing whether human players can outmaneuver the algorithms or fall victim to the same institutional deception that proved so effective against other machines.